Basic statistical tools¶
Moving window statistics¶
moving_window¶
-
hydrobox.toolbox.moving_window(x, window_size=5, window_type=None, func='nanmean')[source]¶ Moving window statistics
Applies a moving window function to the input data. Each of the grouped windows will be aggregated into a resulting time series.
Parameters: - x :
pandas.Series,pandas.DataFrame Input data. The data should have a
pandas.DatetimeIndexin order to produce meaningful results. However, this is not needed and will technically work on different indexed data.- window_size : int
The specified number of values will be grouped into a window. This parameter might have different behavior in case the window_type is not None.
- window_type : str, default=None
If None, an even spaced window will be used and shifted by one for each group. Else, a window constructing class can be specified. Possible constructors are specified in
pandas.DataFrame.rolling.- func : str
Aggregating function for calculating the new window value. It has to be importable from
numpy, accept various input values and return only a single value likenumpy.stdornumpy.median.
Returns: - pandas.Series
- pandas.DataFrame
Notes
Be aware that most window types (if window_type is not None) do only work with either
numpy.sumornumpy.mean.Furthermore, most windows cannot work with the ‘nan’ versions of numpy aggregating function. Therefore in case window_type is None, any ‘nan’ will be removed from the func string. In case you want to force this behaviour, wrap the numpy function into a
lambda.Examples
This way, you can prevent the replacement of a np.nan* function:
>>> moving_window(x, func=lambda x: np.nanmean(x)) array([NaN, NaN, NaN, 4.7445, 4.784 ... 6.34532])
- x :
Linear Regression¶
linear_regression¶
-
hydrobox.toolbox.linear_regression(*x, df=None, plot=False, ax=None, notext=False)[source]¶ Linear Regression tool
This tool can be used for a number of regression related tasks. It can calculate a linear regression between two observables and also return a scatter plot including the regression parameters and function.
In case more than two
Seriesorarraysare passed, they will be merged into aDataFrameand a linear regression between all combinations will be calculated and potted if desired.Parameters: - x : pandas.Series, numpy.ndarray
If df is None, at least two Series or arrays have to be passed. If more are passed, a multi output will be produced.
- df : pandas.DataFrame
If df is set, all x occurrences will be ignored. DataFrame of the input to be used for calculating the linear regression, This attribute can be useful, whenever a multi input to x does not get merged correctly. Note that linear_regression will only use the DataFrame.data array and ignore all other structural elements.
- plot : bool
If True, the function will output a matplotlib Figure or plot into an existing instance. If False (default) the data used for the plots will be returned.
- ax : matplotlib.Axes.Axessubplot
Has to be a single matplotlib Axes instance if two data sets are passed or a list of Axes if more than two data sets are passed.
- notext : bool
If True, the output of the fitting parameters as a text into the plot will be suppressed. This setting is ignored, is plot is set to False.
Returns: - matplotlib.Figure
- numpy.ndarray
Notes
If plot is True and ax is not None, the number of passed Axes has to match the total combinations between the data sets. This is
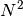
where N is the length of x, or the length of df.columns.
Warning
This function does just calculate a linear regression. It handles a multi input recursively and has some data wrangling overhead. If you are seeking a fast linear regression tool, use the scipy.stats.linregress function directly.